
Stuff happens. Website crashes, security incidents, hardware malfunctions, and so on. The only thing we can do is manage the incident to mitigate the fallout and reduce the stress on the people addressing it.
Automated incident management makes it possible for organizations and individuals to create a playbook with properly curated protocols, workflows, and processes that should be triggered when an incident occurs.
To understand how to automate incident management, we’ve broken down what it means, the benefits, challenges, best practices, tools to consider, and real-life examples.
Let’s get right to it.
Key Takeaways
- Automated incident management removes manual bottlenecks from detection, escalation, and resolution, cutting response times from days to minutes.
- Organizations that automate incident response reduce Mean Time to Detection (MTTD) and Mean Time to Resolution (MTTR) significantly compared to manual approaches.
- A structured incident lifecycle with automated triggers at each phase ensures consistent handling regardless of incident volume or team availability.
- Cross-platform integration between ITSM tools is essential for automated escalation, especially when incidents span multiple teams or external partners.
- AIOps and machine learning are reshaping incident management by predicting potential failures before they cause outages.
- Automated workflows still require human oversight for complex incidents, root cause analysis, and continuous process improvement.
- Choosing the right integration tool requires evaluating bidirectional sync, scripting flexibility, supported platforms, and independent data control.

What is Incident Management?
Incident management is the process of handling every stage of an incident from the moment it appears on your radar until it finally becomes a non-issue.
When you zoom out, incident management applies to every facet of life, from how you manage a flat tire to how emergency services handle extreme weather events.
Zooming into the business world, incident management provides a playbook for addressing events that impact daily business operations. It could be a website or app crash, or a hardware problem (the printer stopped working).
In ITSM (IT Service Management), an incident is any unplanned interruption or reduction in the quality of an IT service. The primary goal is to restore normal service operation as quickly as possible while minimizing the impact on business operations.
What is Automated Incident Management?
Automated incident management (AIM) is the process of eliminating manual processes focused on addressing ongoing problems.
It essentially means removing humans from the equation to increase the accuracy, efficiency, and speed of resolution. Instead of humans, you have workflows, processes, triggers, alerts, and incident management automation working in real time.
So at every stage, there is already an entire algorithm of actions that must be taken automatically to manage the incident and mitigate the disaster.
Incident Management vs. Incident Response
These terms are closely related but cover different ground. Incident management is the full lifecycle, from detection through post-incident review and process improvement. Incident response is the subset of activities focused specifically on containing and resolving the active incident.
Think of it this way: incident response is what happens during the fire. Incident management includes the fire drills beforehand, the response itself, and the review afterwards.
When you automate incident management, you’re automating across the entire lifecycle. When you automate incident response, you’re specifically targeting the containment and resolution phases.
Incident Management vs. Problem Management
Another distinction worth clarifying: incident management focuses on restoring service as fast as possible, while problem management focuses on finding the root cause to prevent recurrence.
For example, if your payment gateway goes down three times in a month, incident management handles each outage individually. Problem management investigates why it keeps happening and implements a permanent fix.
Automated systems can support both. An automated workflow might resolve individual incidents while simultaneously flagging recurring patterns for the problem management team to investigate.
The Automated Incident Management Lifecycle
To get complete control over incidents, you need to automate processes and workflows involved in every phase. This may take the form of scripted rules, predefined templates, or custom connections between your ITSM tools.
Phase 1: Detection and Identification
The first phase is setting up automated monitoring to detect incidents before users report them. This includes application performance monitoring (APM), infrastructure monitoring, log analysis, and synthetic monitoring that simulates user interactions.
For instance, a customer creates a ticket to log a work item or software bug. The system should detect it and flag it for immediate attention. But ideally, your monitoring tools have already identified the anomaly before the customer even notices.
Modern detection systems use threshold-based alerts (CPU usage exceeds 90%), anomaly detection (traffic patterns deviate from baseline), and correlation rules (multiple related alerts trigger a single incident) to reduce noise and catch real problems faster.
Phase 2: Logging and Categorization
The incident is recorded in an incident management system (e.g., ServiceNow, Jira Service Management, Zendesk, Freshservice, Freshdesk) with relevant details: time, user impact, and symptoms.
These incidents are then classified and prioritized based on urgency and impact, as well as the parts of the infrastructure affected.
For instance, the incident could be categorized as a software or hardware problem in order to assign it to the right people. Auto-classification using predefined rules or machine learning can tag incidents based on keywords, affected services, or historical patterns, reducing the manual triage burden.
Phase 3: Escalation and Notification
Based on criteria such as priority, severity, number of users affected, and urgency, the ticket should be forwarded or escalated to the appropriate department.
For instance, high-priority incidents and incident tasks from ServiceNow can be forwarded to the development team in Jira as bugs. Low-priority incidents, such as password resets, can be resolved through a self-service portal and closed automatically.
Once the incidents are escalated, the automated incident management system will send out a notification trigger to alert the assignee or agent responsible for addressing the problem.
Effective automated escalation also includes time-based rules. If an incident isn’t acknowledged within 15 minutes, it escalates to the next tier. If it isn’t resolved within the SLA window, it reaches management. This prevents tickets from getting stuck in queues.
Phase 4: Investigation and Diagnosis
For severe software defects, root cause analysis and deeper investigation are conducted to pinpoint the source or cause of the incident or bug. This also involves going over event logs and reports to figure out what went wrong and where things started breaking.
Automated diagnostic tools can pull relevant data from multiple systems, including recent deployment logs, configuration changes, and dependency maps, to give responders a head start. Instead of spending the first 30 minutes gathering information, the team gets a pre-assembled incident context package.
Phase 5: Resolution and Recovery
The information from running diagnostics will tell the team manager where to forward the incident or the team responsible for providing a solution.
For instance, software defects will go to the development team for resolution, while minor UI problems can be addressed and resolved by the customer service team.
Some incidents can be resolved entirely through automation. Automated remediation actions like restarting services, scaling infrastructure, rolling back deployments, or clearing caches can fix known problem types without human intervention. For novel problems, automation handles the data collection while humans focus on the fix.
Phase 6: Closure and Validation
After the incident is resolved, the status is automatically updated, and the ticket is closed according to the automation rules. If the ticket is closed in ServiceNow, the status of the Freshservice ticket will automatically be changed to “Resolved.”
For unresolved problems, the automated workflows can trigger predefined actions, such as sending notifications or escalating the incident further after a certain amount of time.
Validation steps should also be automated. After resolution, synthetic checks or monitoring thresholds can confirm the service is actually restored before the ticket closes. This prevents premature closure and avoids those frustrating “resolved but still broken” scenarios.
Phase 7: Post-Incident Review and Continuous Improvement
For major incidents, a review is conducted to understand what went wrong and how to prevent recurrence.
Subsequently, the incident logs will be available so that your team will be able to get a grasp of the following:
- Time of first detection
- Severity level
- Team members involved
- Number of affected users or devices
- Number of hours from detection to resolution (MTTR/MTTD)
This report will provide a broader context for what went wrong and assess the effectiveness of the automated incident management software (and the team in general) in managing the situation.
This data will now be analyzed using machine learning and artificial intelligence to identify recurring patterns, which will come in handy when predicting potential failures and optimizing the system for future incidents.
Post-incident reviews should also feed back into your automation rules. Every major incident is an opportunity to add new automated responses, refine escalation paths, or improve detection thresholds.

Discover how to integrate Jira Service Management with Jira Software and other systems.
The Role of AIOps in Automated Incident Management
AIOps (Artificial Intelligence for IT Operations) represents the next evolution in automated incident management. Rather than relying solely on predefined rules and static thresholds, AIOps applies machine learning and big data analytics to IT operations data.
How AIOps Enhances Incident Management
Traditional automation reacts to known conditions. AIOps learns from historical data to identify patterns humans would miss. It can correlate events across multiple monitoring systems, suppress duplicate alerts, and predict failures before they occur.
For example, an AIOps platform might notice that disk I/O latency on a specific database server increases gradually over 72 hours before a crash. It can flag this pattern and trigger preventive action like load balancing or storage expansion before the outage happens.
Predictive Incident Management
The shift from reactive to predictive incident management is significant. Instead of waiting for a threshold breach, predictive systems analyze trends and anomalies to forecast potential incidents.
This includes capacity planning (predicting when resources will be exhausted), failure prediction (identifying components likely to fail based on historical patterns), and change risk assessment (evaluating the likelihood that a planned change will cause an incident).
Alert Noise Reduction
One of the biggest practical benefits of AIOps in incident management is reducing alert fatigue. IT teams often deal with thousands of alerts daily, many of which are false positives or duplicates. AIOps can group related alerts into a single incident, suppress non-actionable alerts, and prioritize based on actual business impact rather than technical severity alone.
Incident Severity Levels and Priority Matrices
Effective automation depends on well-defined severity classifications. Without clear criteria, automated escalation rules can either over-escalate minor problems (wasting senior team time) or under-escalate critical ones (delaying response to real emergencies).
Standard Severity Levels
Most organizations use a four-tier or five-tier severity model:
Critical (SEV-1): Complete service outage affecting all users. Examples include a production database failure, a payment processing system down, or a security breach with active data exfiltration. Automated response should include immediate page to on-call engineers, executive notification, and status page update.
High (SEV-2): Major functionality degraded but service is partially available. Examples include slow response times affecting 50% or more of users, a key feature unavailable, or a backup system failure. Automated response should include team channel alert, escalation timer, and affected customer notification.
Medium (SEV-3): Minor functionality impacted with a workaround available. Examples include a non-critical feature bug, intermittent errors affecting a small user segment, or a performance degradation within tolerance. Automated response should include standard ticket routing and SLA timer.
Low (SEV-4): Cosmetic problems or minor inconveniences. Examples include UI alignment problems, typos in system messages, or feature requests misclassified as incidents. Automated response should include backlog categorization.
Building Priority Matrices
Priority is determined by combining severity (business impact) with urgency (how quickly it needs to be resolved). An automated priority matrix cross-references these factors to assign the appropriate response level.
For instance, a SEV-2 incident affecting a major client during their peak business hours might be treated as P1 priority, while the same severity during off-hours might be P2. Automated systems can factor in time zones, customer tier, and business calendar when assigning priority.
Examples of Automated Incident Management
Some real-world examples of automated incident management in the business/IT world:
Website and Application Performance Failures
Case: A SaaS company’s payment gateway stops processing transactions during peak hours, directly impacting revenue.
Solution: Automated monitoring detects the failure within seconds. An incident is automatically created in Freshdesk and forwarded to the IT team using ServiceNow. This triggers a bug report instantly, pages the on-call engineer, and updates the public status page.
Real-World Application: The automated workflow simultaneously checks recent deployments, identifies a database connection pool exhaustion, and triggers an auto-scaling rule while the engineering team investigates the root cause. Total detection-to-first-response time: under 3 minutes.
Internal Service Requests with Self-Service Resolution
Case: Employees across multiple offices frequently submit password reset requests and basic access requests, consuming IT support capacity.
Solution: An automated self-service portal handles common requests without human intervention. Employees create a Freshservice request and receive a password reset link within minutes.
Real-World Application: The system identifies password reset requests through keyword classification, validates the user’s identity through MFA, and executes the reset automatically. Tickets that can’t be auto-resolved (like requests for elevated access) are escalated to the appropriate approval chain. This reduces L1 ticket volume by 30-40% in most organizations.
Cross-Company Incident Escalation for MSPs
Case: A managed service provider (MSP) detects an infrastructure incident affecting multiple clients simultaneously.
Solution: The triggered automation generates tickets in ServiceNow or Freshservice and sends email alerts to all affected clients simultaneously to resolve the problem as fast as possible.
Real-World Application: When a shared infrastructure component fails, the automated system creates parent-child incident relationships, with the master incident tracked internally and individual client tickets providing client-specific impact details and communication. Each client receives updates relevant to their environment without the MSP manually duplicating information across systems.
Security Incident Response
Case: The security operations center (SOC) detects a potential data exfiltration attempt outside business hours.
Solution: Automated security playbooks trigger containment actions immediately, without waiting for human analysts.
Real-World Application: Firewall rules automatically block suspicious IPs. The affected endpoint is isolated from the network, and the EDR system captures a forensic snapshot. The system pages the security on-call team with a pre-assembled evidence package. Automated scripts initiate a broader sweep across all endpoints to check for lateral movement. This limits the blast radius within minutes rather than the hours a manual response would take.
Hardware and Infrastructure Monitoring
Case: A printer fleet across multiple offices needs proactive management to prevent workflow disruptions.
Solution: IoT-enabled monitoring detects hardware status changes and triggers automated responses.
Real-World Application: A printer running out of ink triggers a supply order automatically while switching print jobs to the nearest available device. For more critical hardware, a physically compromised laptop triggers an immediate revocation of user access and certificate invalidation, preventing potential data loss.
Cross-Platform Development Escalation
Case: A fintech company runs its customer support on Zendesk while its development team uses Jira. Critical bugs reported by customers need to reach developers without manual handoffs.
Solution: Integration between Zendesk and Jira automatically creates work items for bug reports that meet severity criteria, with bidirectional status updates.
Real-World Application: When a customer reports a transaction processing error, the support agent tags it as a bug in Zendesk. The automated integration creates a corresponding Jira work item with full context (customer tier, reproduction steps, screenshots). As the developer updates progress in Jira, the Zendesk ticket reflects those changes, keeping the support agent informed without back-and-forth messages.
Why is Automated Incident Management Important?
Some people insist that humans should still be in charge of managing incidents. However, current trends have shown that automated incident management is the way forward.
Faster Detection and Resolution
According to FRSECURE, it typically takes businesses 197 days to discover a breach and 69 days to manage it.

Think about that. That’s months of the breach occurring, and in the current world of lightning-speed cyberattacks, you might as well give the attackers a cup of coffee.
With automated incident management, you can detect breaches faster, sometimes within minutes. This will limit the potential damage to your system infrastructure as well as the level of penetration.
With limited or no human intervention, you can effectively reduce the Mean Time to Detection (MTTD) and Mean Time to Resolution (MTTR). Organizations with mature automation practices often report 60-80% reductions in MTTR compared to fully manual processes.
Less Room for Human Error
The goal of automated incident management is to keep humans away from the response cycle. And there is a point. Humans can crack under stress, which can lead to negligence and catastrophic errors.
Let’s use a security incident, for example. The automation can instantly analyze and detect abnormal activity, then escalate it to the service desk within seconds.
If a human is in charge, they could miss the early indicators or even assign the ticket to the wrong person. These precious minutes can be crucial in security scenarios.
Automation also ensures consistent handling. The same playbook runs at 3 AM on a Sunday just as effectively as at 10 AM on a Tuesday. Human performance varies with fatigue, stress, and workload. Automation doesn’t.
Better Context for Your Team
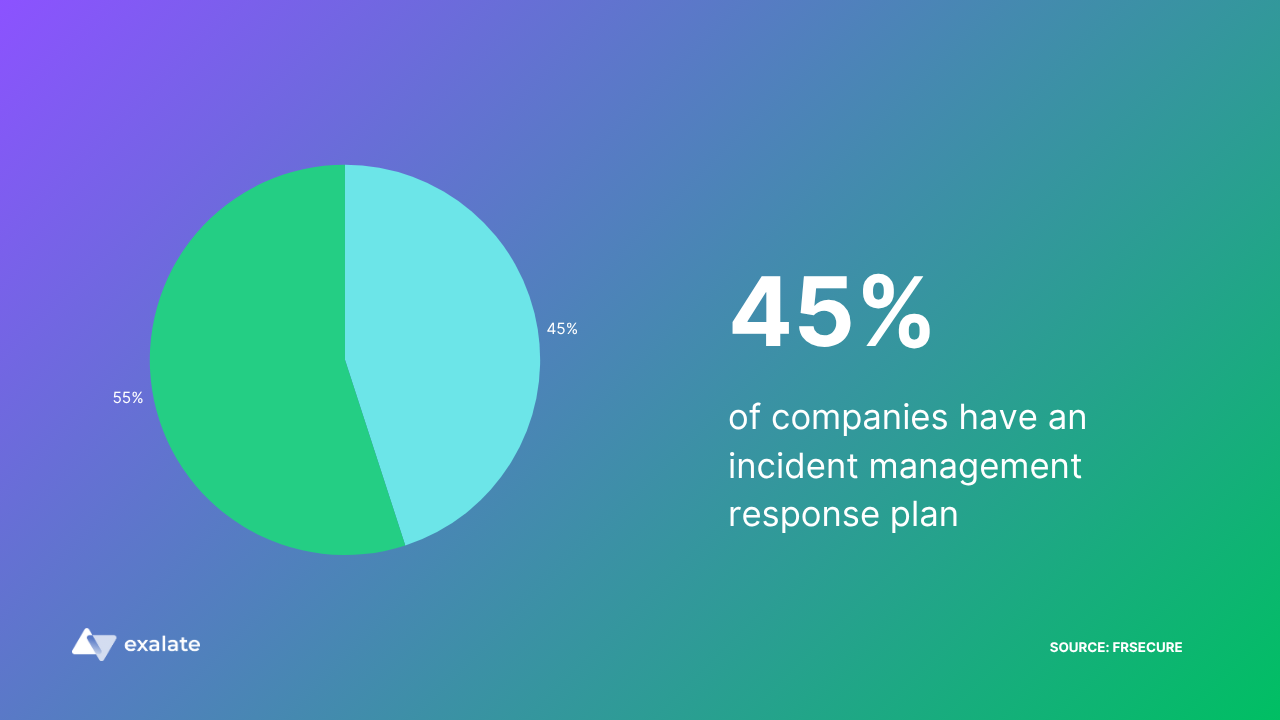
Automated incident management doesn’t cut out humans completely. It places them in supervisory roles where they can act with a better context. Even at that, only 45% of companies have an incident response plan in place.
When the automation gathers the logs and analyzes the cause and source of the incident, all the key info will be available to your team to initiate the corrective or preventive procedure. No need for guesswork or wasted efforts.
If they’re using an ITSM system like ServiceNow or Freshservice, they can automatically update other teams or companies involved in the incident. Cross-platform integrations make this seamless when incidents span organizational boundaries.
Transparent Logging and Reporting
Automated workflows save logs and forensic data, which provides valuable intel about the incident.
Your team can review the logs afterwards to generate thorough incident reports, which can now be used in post-incident review and communication with stakeholders.
If humans were involved, one team member could forget a key piece of information, which is common in the heat of the moment. Automated logging captures everything, including timestamps, actions taken, communications sent, and resolution steps, creating a complete audit-ready record.
Competitive Advantage Through Speed
Your team’s ability to manage incidents automatically gives you a massive competitive edge over other organizations in your industry.
Here is an example.
The payment gateway is down on your website. So a ticket is created in Zendesk and replicated in Jira Service Management for the IT staff. This instantaneous ticket escalation increases the likelihood of a faster resolution. As a result, you can keep the customer satisfied.
If your competitors rely on manual processes, customers will likely bounce from them and defect to your product. Every second matters.
Reduced Expenses and Downtime Costs
The faster you can detect and resolve an incident, the smaller the expenses. In some cases, you can completely automate the incident management process without any humans in the cycle.
Automating incident response means that you spend less time and money trying to figure out the solution. This also means you don’t lose productive business hours, as well as conversion opportunities, while your services are down.
In essence, better uptime and faster incident management translate to more money in your coffers. Gartner estimates that the average cost of IT downtime is $5,600 per minute. Even modest improvements in MTTR can save organizations hundreds of thousands of dollars annually.
Improved SLA Compliance
When incident response is automated, SLA adherence becomes more predictable. Automated escalation timers ensure that no ticket sits unattended beyond the agreed response window. Priority-based routing sends the right incidents to the right teams without human delays in triage.
For organizations managing external SLAs with clients or partners, this consistency is critical. Automated systems can track SLA metrics in real time and trigger preventive escalations before an SLA breach occurs, rather than reporting the breach after the fact.
Why is Incident Management Difficult?
Automation sounds like a plug-and-play scenario. In reality, incident management using automation presents numerous challenges.
System Integration Complexity
The reality of incident management is that you need to integrate ticketing software, monitoring tools, and communication systems to interact.
And since they all have different API configurations, this can be a major headache. Conversion errors can result in incomplete data transfers and inaccurate reporting.
Sometimes, the complexity comes from legacy systems, which do not support modern automation and workflow orchestration.
To overcome this challenge, you need to set up an integration using automated incident management tools, such as Exalate. This tool will help you create a bidirectional script-based integration to control the flow of information in real time.
Exalate comes with Aida, an AI-powered Groovy-based scripting assistant for complex customizations. Aida helps teams generate sync rules faster by providing scripting assistance based on your integration requirements, reducing the learning curve for teams new to Groovy scripting.
Data Security Risks
When data flows between systems, the chances of breaches and compromise increase. And if the attack has infiltrated your automated workflows, it could create further chaos within the organization.
To address security concerns, focus on solutions that incorporate advanced security protocols, robust encryption, role-based access control, and multi-factor authentication (MFA). Also, carry out regular security audits to make sure your firewalls and security protocols are up to date.
When evaluating integration tools specifically, look for those with ISO 27001:2022 certification and a transparent security posture. Exalate, for example, publishes its security practices through its Trust Center, giving teams visibility into compliance and data handling practices.
Scalability and Cost Management
Automating incident detection and response for a single module is straightforward. But when you have multiple workflows, teams, and clients, the volume of incidents can skyrocket pretty quickly.
This often requires scaling up your current incident management response, and of course, you have to pay more money.
To keep your system flexible and scalable without spending beyond your budget, focus on scalable incident management solutions designed to accommodate surges and spikes without noticeable performance issues. Look for solutions that charge based on your integration scope rather than per-user pricing, so costs don’t scale linearly with team size.
Resistance to Change
As AI takes over jobs, employees will naturally resist automation. This often results in teams preferring to manage incidents “the old way.” Obviously, this has procedural and financial implications for your business.
To break through that resistance to automation, educate your team on the importance of automation. Hammer home the point that the automation is there to improve their effectiveness rather than push them out the door.
This may also involve rolling out the incident automation process in phases until the team becomes accustomed to it.
Alert Fatigue and Noise
This is one of the most underestimated challenges. Poorly configured automation can generate more noise than it eliminates. When everything triggers an alert, teams start ignoring alerts altogether.
The solution is tiered alerting with clear severity thresholds, alert grouping to combine related notifications, and regular tuning based on false positive rates. Your automation should reduce the number of alerts your team sees, not increase it.
Poor Cross-Team Communication
Even though automated systems are managing incidents for your organization, humans still need to stay in the loop to coordinate a cohesive response.
This close collaboration will help them determine what works and what needs to be optimized for future reference. The communication could take the form of status updates, internal comments, or work notes shared among team members.
Cross-platform integrations help here. When your support team in Zendesk, development team in Jira, and infrastructure team in ServiceNow all see the same incident data in their own tools, communication gaps shrink. Each team works in their preferred environment while staying synchronized through bidirectional data flows.
Learn everything worth knowing about integrating Jira Service Management with ServiceNow.
What to Look for in Automated Incident Management Tools
Choosing the right tools for your incident management stack requires evaluating several capabilities.
Monitoring and Detection Tools
These are the eyes of your automated system. Application performance monitoring (APM) tools, infrastructure monitoring platforms, and log analysis systems form the detection layer. Look for tools that support custom threshold configuration, anomaly detection, and integration with your ticketing system for auto-incident creation.
Ticketing and ITSM Platforms
Your ITSM platform is the central hub where incidents are tracked, categorized, escalated, and resolved. Platforms like ServiceNow, Jira Service Management, Freshservice, Freshdesk, and Zendesk each offer varying levels of automation capability. Evaluate them based on workflow automation depth, API flexibility, and how well they support your specific escalation paths.
Integration and Orchestration Tools
This is where everything comes together. When incidents span multiple teams using different platforms, you need integration tools that sync data bidirectionally in real time. Key capabilities to evaluate include scripting flexibility for complex field mappings, support for multiple connectors across your tool stack, independent data control (each side should manage their own sync rules without depending on the other), and the ability to handle high-volume sync during incident spikes without performance degradation.
Communication and Alerting
Incident communication needs to reach the right people through the right channels. This includes on-call management and paging systems, ChatOps integration with platforms like Slack or Microsoft Teams, status page automation for external communication, and stakeholder notification workflows that adapt based on incident severity.
Runbook Automation
For known incident types, runbook automation can execute predefined remediation steps without human intervention. This includes server restarts, failover triggers, cache clearing, and configuration rollbacks. The best runbook automation tools integrate directly with your monitoring and ticketing systems to create a closed-loop response.
Best Practices for Automated Incident Management
Let’s discuss the best practices to follow for hitch-free incident management automation.
Define Incident Response Policies
Teams should define roles to control every stage of incident management, from detection to assessment to escalation. This will establish a governance policy to regulate the interaction between automated systems and humans. Include clear criteria for when automation should hand off to humans, especially for novel or complex incidents that don’t match known patterns.
Follow a Consistent but Evolving Playbook
When configuring and automating your company’s incident management playbook, focus on outlining clear-cut instructions for different types of incidents based on severity, urgency, financial impact, and other factors. Use a dynamic playbook to stay adaptable to technological changes.
Review your playbooks quarterly. Incidents evolve, infrastructure changes, and what worked six months ago might not be optimal today.
Test Through Simulated Incidents
Use simulated incidents to ascertain the efficacy and applicability of the response mechanism. This will help you identify weaknesses and blind spots that require attention.
Testing should be continuous, rather than a one-time endeavor. Many organizations run “game day” exercises where they inject real failures into staging or production environments (with safeguards) to validate their automated responses under realistic conditions. So test, optimize, then implement.
Implement Tiered On-Call Rotations
Automation handles the first line of defense, but humans need to be available for escalation. Implement on-call rotations with clear escalation paths so that automated alerts reach available responders. Avoid single points of failure in your on-call setup. Backup responders and automatic re-routing for unacknowledged pages should be standard.
Build Feedback Loops Into Every Major Incident
Post-incident reviews shouldn’t just document what happened. They should feed directly into your automation rules. Every major incident is a chance to add a new automated response, refine an escalation threshold, or improve detection coverage.
Track the ratio of incidents handled fully by automation versus those requiring human intervention. Over time, this ratio should shift toward automation as your playbooks mature.
Add Security Measures Throughout
Stay up to date with compliance and security requirements. Invest in additional security features to safeguard your automated workflows and data, both at rest and in transit. This includes encrypted data synchronization between platforms, role-based access controls on automation rules, and regular reviews of integration permissions.
Educate Your Team Continuously
Dedicate sufficient time and resources to teaching your team members the importance of automated incident management and how to respond to it. Encourage them to learn about new technologies, trends, and best practices for managing automated systems.
Overall, automated incident management can only work if every person involved plays an active role in bridging the gap between human and machine.
Exalate for Automated Incident Management
Exalate is a cross-company integration platform that connects ITSM solutions, work management systems, and CRMs. It plays a key role in automating the escalation, synchronization, and cross-platform communication that incident management demands.
With Exalate, your team can connect with various incident and task management systems, including Zendesk, ServiceNow, Freshdesk, Freshservice, Service Desk Plus, Jira Service Management, Asana, Azure DevOps (including Azure DevOps Server), and more.
Why Exalate Fits Incident Management Workflows
- Bidirectional, real-time sync: When an incident is created in ServiceNow and escalated to Jira, both sides stay updated automatically. Status changes, comments, attachments, and custom field updates flow both ways without manual intervention.
- Groovy-based scripting engine: Exalate’s scripting engine gives teams full control over what data syncs, how it transforms, and under what conditions. You can write rules that escalate only critical incidents, map severity levels between platforms, or filter out internal comments from external sync.
- Aida for faster configuration: Aida, Exalate’s AI-powered scripting assistant, helps teams generate sync rules based on natural language descriptions of their integration requirements. This reduces the time spent writing Groovy scripts from scratch, especially for teams that are new to the platform.
- Trigger-based control: Exalate triggers let admins define exactly which work items, incidents, or tickets should be synchronized based on conditions like priority, project, status, or custom fields. This granular control prevents unnecessary data flow and ensures that only relevant incidents reach the right teams.
- Independent control per side: Each organization in an Exalate integration manages its own sync rules independently. This is especially important for MSPs and cross-company incident management, where each party needs to control what data enters and leaves their environment without depending on the other side’s configuration.
- Broad platform coverage: Beyond the platforms already mentioned, Exalate supports custom connectors, which means teams can integrate with proprietary or niche systems that aren’t covered by out-of-the-box connectors.
Discover how Exalate integrates into your automated incident management strategy. Book a call with our engineers right away.
Frequently Asked Questions
What is automated incident management?
Automated incident management is the process of using workflows, triggers, and predefined rules to handle the full incident lifecycle, from detection and logging through escalation, resolution, and post-incident review, with minimal or no manual intervention.
How does Exalate support automated incident management?
Exalate connects ITSM platforms like ServiceNow, Jira Service Management, Freshservice, Freshdesk, and Zendesk through bidirectional integrations. It automates the cross-platform escalation of incidents, syncs status updates and comments in real time, and gives each side independent control over their sync rules using a Groovy-based scripting engine.
Can Exalate integrate ServiceNow with Jira for incident escalation?
Yes. Exalate supports bidirectional sync between ServiceNow and Jira. High-priority incidents in ServiceNow can automatically create Jira work items for the development team, with status changes, comments, and custom fields syncing both ways.
What ITSM platforms does Exalate support?
Exalate supports ServiceNow, Jira Service Management, Jira Cloud, Zendesk, Freshservice, Freshdesk, Service Desk Plus, Azure DevOps (including Azure DevOps Server), Asana, GitHub, and Salesforce, among others. It also supports custom connectors for proprietary or niche systems.
What is the difference between incident management and incident response?
Incident management covers the entire lifecycle of an incident, from detection through post-incident review and continuous improvement. Incident response is the subset focused specifically on containing and resolving the active incident. Automated incident management tools like Exalate address the full lifecycle by ensuring seamless data flow across teams and platforms at every phase.
How does AIOps improve automated incident management?
AIOps applies machine learning to IT operations data to enhance incident management. It reduces alert noise by correlating related events, predicts potential failures based on historical patterns, and automates root cause analysis. When combined with cross-platform integrations through tools like Exalate, AIOps-driven insights can trigger automated escalation workflows across teams.
Can automated incident management work for cross-company scenarios?
Yes. Cross-company incident management is one of the most impactful use cases for automation. Exalate’s independent control model means each company manages its own integration rules without exposing internal processes to the other party. This is particularly valuable for MSPs managing multiple client environments and enterprises collaborating with external vendors.
How do you reduce alert fatigue in automated incident management?
Alert fatigue is reduced through alert grouping (combining related alerts into a single incident), tiered severity thresholds, suppression of known false positives, and regular tuning based on historical alert data. Cross-platform tools like Exalate can further reduce noise by ensuring that only incidents meeting specific criteria are escalated across systems.
What metrics should you track for automated incident management?
Key metrics include Mean Time to Detection (MTTD), Mean Time to Acknowledge (MTTA), Mean Time to Resolution (MTTR), percentage of incidents resolved by automation without human intervention, SLA compliance rate, false positive rate for alerts, and the ratio of recurring incidents to unique incidents. These metrics help teams evaluate the effectiveness of their automation and identify areas for improvement.
Recommended Reads:
- How to Set Up a Bidirectional Jira Service Management Integration with Jira Software
- How Jira Service Management Integration With ServiceNow Can Save Your Service Delivery
- ITSM Integration: Simplify Your IT Services Like Never Before
- Automated Integration: A Key to Scalable and Agile Business Operations
- The Reality of Business Process Integration
- Understanding Workflow Orchestration for Complex Business Processes


